
review-paper-The Semantic Reader Project
ref from my vault: [[paper-The Semantic Reader Project-Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces]]
While searching for a way to augmented how we read research papers, I found this interesting project and its proof-of-concept website that 10+ scholars from different universities unite to solve the same big problem that many of us faced it for decades.
In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers, based on a static PDF format, has remained largely unchanged for many decades.(p.1)
WIP (I need to add my opinions too)
They define 5 broad challenges for develop this system.
- Discovery
- problems:
- the interaction cost caused by jumping back-and-forth between inline citations
- Some citation are move relevant to the current reader than others.
- many relevant research papers are not cited in a research paper in the first place, for example, because they were published afterwards.
- while inline citations reference cited papers, they do not typically reference specific locations in the cited paper
- CiteSee: scores and highlights inline citation based on relevance, also have pop-up UI to show how each citations connected to reader’s previous activities; library folders they were saved.

- CiteRead: reference to specific locations in the cited paper by looking for overlapping spans of text.

- problems:
- Efficiency
- Problems:
- Scholars often have to read paper non-linearly, jump back-and-forth, this can be a distraction by causing readers tto constantly switch contexts.
- for blind and low-vision reader, navigating between sections and retrieving content can be very challenging, auditory skimming didn’t help that much
- Scim: highlight key categories of info in the paper.

- Ocean: for blind and low-vision readers: providing bi-directional hyperlinks with viewport-preserving function, and feature to create and share paper links during reading.
- Problems:
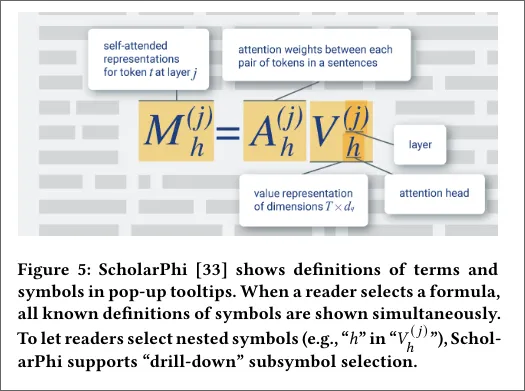
- Comprehension
- ScholarPhi: interactive aids that present definitions of terms and symbols.
- PaperPlain: LLM summarize on each sections.

- Papeo: by linking excerpts of talk videos to corresponding paper passages. To grant authors more control over how their work is presented, we developed an AIsupported authoring interface for linking paper passages and videos efficiently, they said.

- Synthesis (scaffolding with related work section)
- Threaddy: preserve reading flows, reducing the cognitive and interaction costs of clipping and note taking by select and save sentences into a sidebars from related work section, then let readers organize clips collected across paper into a hierarchy of threads to form their view of the research landscape, and recommend other relevant papers for each thread.
- (this feature reminds me of roamresearch, heptabase’s card, and obsidian canvas, wanna compare them with this)
- (I’m really interested in this feature, sadly that they didn’t show it on the paper.)
- Relatedly: LLM tool that generate short and descriptive titles for each paragraph.
- Threaddy: preserve reading flows, reducing the cognitive and interaction costs of clipping and note taking by select and save sentences into a sidebars from related work section, then let readers organize clips collected across paper into a hierarchy of threads to form their view of the research landscape, and recommend other relevant papers for each thread.
- Accessibility
- many research papers are based on a static PDF format
- bad for accessibility; many reading tools for people who prefer reading with a small mobile device or people with disabilities often not function properly.
- solution: converts to XML or HTML formats.
- many research papers are based on a static PDF format
Discussion:
- concern: Ethics of augmented papers
- risk of a “rich get richer” from relevant search system.
- “should carefully consider additional signals of relevance such as semantic similarity to surface newer and overlooked papers.”
- concern: How to be thoughtful by those tools.
- “A related issue is around systems for more efficient reading or synthesis, which may encourage readers to take shortcuts that lead to incorrect understanding, sloppy research, or even outright plagiarism. Instead of simply seeking to increase reading throughput uniformly, our systems should enable triage, so that readers can dedicate time for thoughtful and careful reading when the content is important.”